


Stop Overpaying for AI: How to Cut Your Industrial LLM Costs by 73%
During strategic conversations across our customer base, we often receive the following question from IT leaders and data architects: "If we already have our process data in a data lake, and LLMs can query anything, why would we still need a purpose-built analytics platform like TrendMiner?"
We welcome the question. The AI landscape is moving fast, and every tool in your stack should earn its place. So rather than guess or stick to qualitative answers, we decided to test the premise head-on: with a controlled benchmark, real industrial analytics tasks, and hard numbers. Here’s what we found.
Note: In most cases, customers mean a (private) cloud data lake deployment, so that’s also the assumption we’ll use throughout this article.
The TL;DR Benchmark Results

TrendMiner’s Analytics Agent outperformed the “just query the data lake” approach across every meaningful dimension: quality, speed, cost, and reliability. We’ll dive deeper into the experiment, methodology, and detailed findings further on. But first, let’s look at why the gap is so large, and what that means for your analytics architecture going forward. Because this isn’t a story about TrendMiner versus GenAI or TrendMiner versus data lakes. It’s about understanding the strengths of each, and why they’re potentially better together.
Six Reasons a Data Lake Can’t Replace Purpose-Built Industrial Analytics
Before we get into benchmark data, here’s the strategic picture. These are the patterns we see across the landscape, and the reasons why simply pointing an LLM at raw process data tends to fall short.
1. Industrial intelligence is embedded, not bolted on
TrendMiner was built from day one for process manufacturing. That means validated analytics, contextual know-how about how industrial time-series data behaves, and purpose-built workflows. None of these exist in a generic data lake. An LLM querying raw tables has no concept of batch phases, process limits, or what a “low max concentration” means for product quality. TrendMiner brings that meaning to the table.
2. Consistency matters when agents scale
A critical requirement for professional industrial AI and analytics platforms like TrendMiner is deterministic behavior: same analysis, same results, every time. That reliability becomes critical as, in the future, organizations may move toward agentic architectures where potentially dozens of AI workflows run in parallel. If your analytical foundation produces unpredictable or hard to reproduce outputs, you can’t build trustworthy automation on top of it.
We saw this firsthand in our testing. Even with the most advanced models, on the data lake, repeated runs of the same task returned different results: one run identified 240 batches, another found 235, a third landed on 238. The differences were buried deep in the Python and SQL logic the agent generated each time: subtle variations in boundary conditions, filter thresholds, or date handling. And when you want to understand where the discrepancy came from, you’re not exploring your process data; you’re dissecting auto-generated code. That’s a fundamentally different activity from what a process engineer should be spending their time on. On TrendMiner, the same query returns the same result, and every step is traceable back to the data itself, not to an intermediary code layer you didn’t write.
3. Explainability builds trust; black-box queries don’t
Process experts need to validate what the AI did and why. TrendMiner’s workflows are transparent and auditable: every step can be reviewed, repeated, and verified by a domain expert. When an LLM writes ad-hoc SQL (or other query languages) to run against the data lake, the path from question to answer is opaque, unrepeatable, and nearly impossible for a process engineer to validate.
This matters even more when the analysis carries regulatory or financial weight. Emission reporting, energy accounting, environmental compliance. These are areas where results are directly tied to billing, audits, and legal obligations. You need to be able to demonstrate exactly how a number was derived, not point to a chain of auto-generated SQL queries that may differ from run to run. An auditor won’t accept “the AI figured it out” as documentation.
4. Speed and cost compound at enterprise scale
A single root cause analysis running with a 73% lower token consumption and twice as fast is noteworthy. Multiply that across hundreds of daily analyses, dozens of AI agents, and multiple production sites, and the economic case becomes overwhelming. Token efficiency isn’t an academic metric; it’s directly tied to how much analytical work you can do within a given budget.
But token costs are only half the story. The data lake approach often also requires an expensive compute layer to execute all those SQL queries, and that cost is typically substantial. During our benchmark, for one of the tasks requiring more data, we burned through roughly €50 in data lake compute credits just running the task three times to validate its consistency. That’s on top of the LLM token costs. Now imagine scaling that across hundreds of engineers, each running multiple analyses per day. The data lake compute bill alone could dwarf any other cost.
5. Flexibility without lock-in
TrendMiner doesn’t force you into a single vendor’s ecosystem. Bring your own LLM. Combine data from multiple sources. Deploy self-hosted or in the cloud. The integration layer adapts to your infrastructure instead of asking your infrastructure to adapt to assumptions about how your data is structured.
6. You shouldn’t need a cloud migration to use AI
There’s a prerequisite baked into the “just query the data lake” argument that often goes unspoken: it assumes all your process data is already centralized in a cloud data lake. For many manufacturers, it isn’t. Historians are on-premise. Data is distributed across sites. A full cloud migration can easily become a multi-year, multi-million-dollar project, and telling your operations team they can’t benefit from AI until that’s done is a non-starter in this high-velocity environment.
TrendMiner, true to its vision to democratize AI and analytics, connects directly to your existing data sources, whether on-premise historians, cloud environments, or hybrid architectures. That means the engineers who know your process best can start getting AI-driven insights today, without waiting for an infrastructure transformation to finish.
And here’s the thing: even if you do go the data lake route, TrendMiner still fits right on top. With our caching and indexing layer sitting between the AI and the data lake, you get the best of both worlds: the centralized storage benefits of a data lake with controlled query costs, purpose-built analytics, and an AI integration layer that is fit for purpose. You don’t have to choose one or the other.
We Tested It. Here’s What Happened.
To put tangible numbers behind these arguments, we designed a series of controlled benchmark tests: real industrial analytics tasks, performed by two AI approaches side by side. One used TrendMiner’s Analytics Agent, a purpose-built integration that exposes industrial tools to the AI model. The other used the data lake’s own available agents and MCP connectivity, giving the same AI models access to the underlying data.
We chose a cloud data lake setup because it’s an architecture many of our customers are considering, attracted by low entry costs and cheap storage. And on paper, it makes sense: getting started is affordable, and the promise of having all your data in one place is compelling. But there’s a catch: the true cost only becomes visible once you actually start using the data. Query costs scale aggressively. Compute needs to be carefully managed. Scaled up for workloads, scaled back down to avoid runaway bills. You need dedicated people optimizing infrastructure, setting guardrails, and managing access. It’s a platform usually geared towards data engineers with deep expertise, delivering great value, but not one that directly empowers the broader population of process engineers and operators to self-serve. That distinction matters when we talk about AI-driven analytics at scale.
The following tasks were designed and tested as representative for typical use cases done on the operations floor on a daily basis.
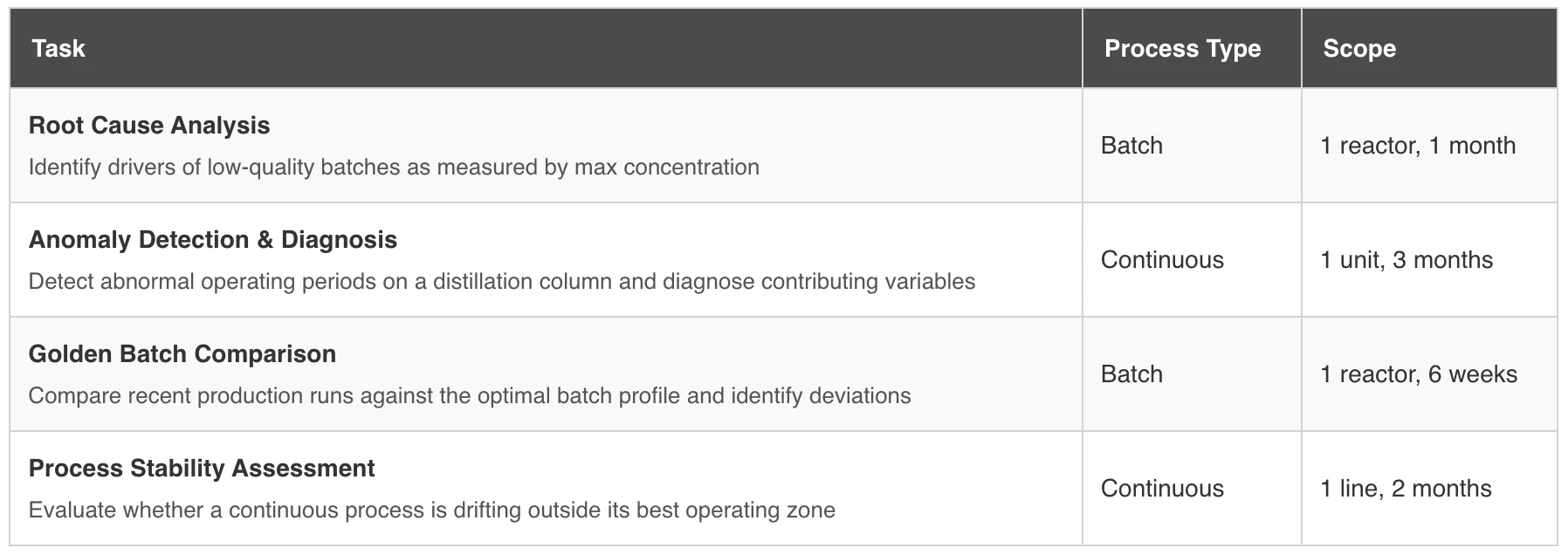
Each task was run across three Anthropic Claude models: Claude Haiku 4.5 (lightweight), Claude Sonnet 4.6 (mid-tier), and Claude Opus 4.6 (frontier-class). We selected Anthropic’s model family because they can currently be considered best-in-class for agentic and analytical workloads, though we expect the findings to generalize well to other model providers. The core dynamic is architecture-dependent, not model-dependent.
Every model ran each task multiple times per integration, so we could assess not just quality but consistency: does the same setup produce reliable results, or do you get a different answer every time?
Quality was scored by an independent evaluator on a 1–5 scale, assessing the analytical depth of the output: did the AI correctly identify the relevant variables, form a sound hypothesis, retrieve the right data to support it, and arrive at a defensible conclusion? A score of 5 means a process engineer could act on the analysis with confidence. A score of 1 means the output was superficial, incorrect, or incomplete to the point of being unusable.
The Results in Detail
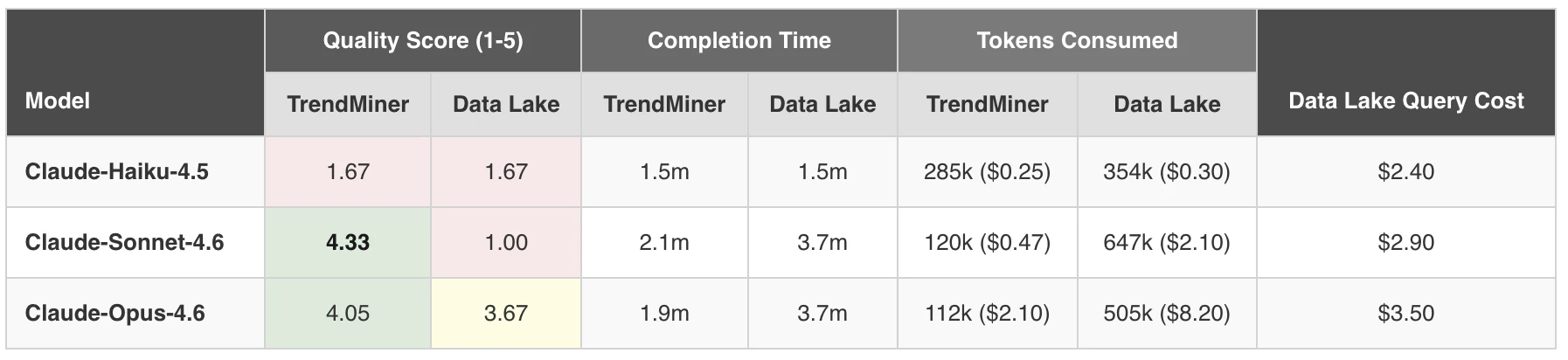
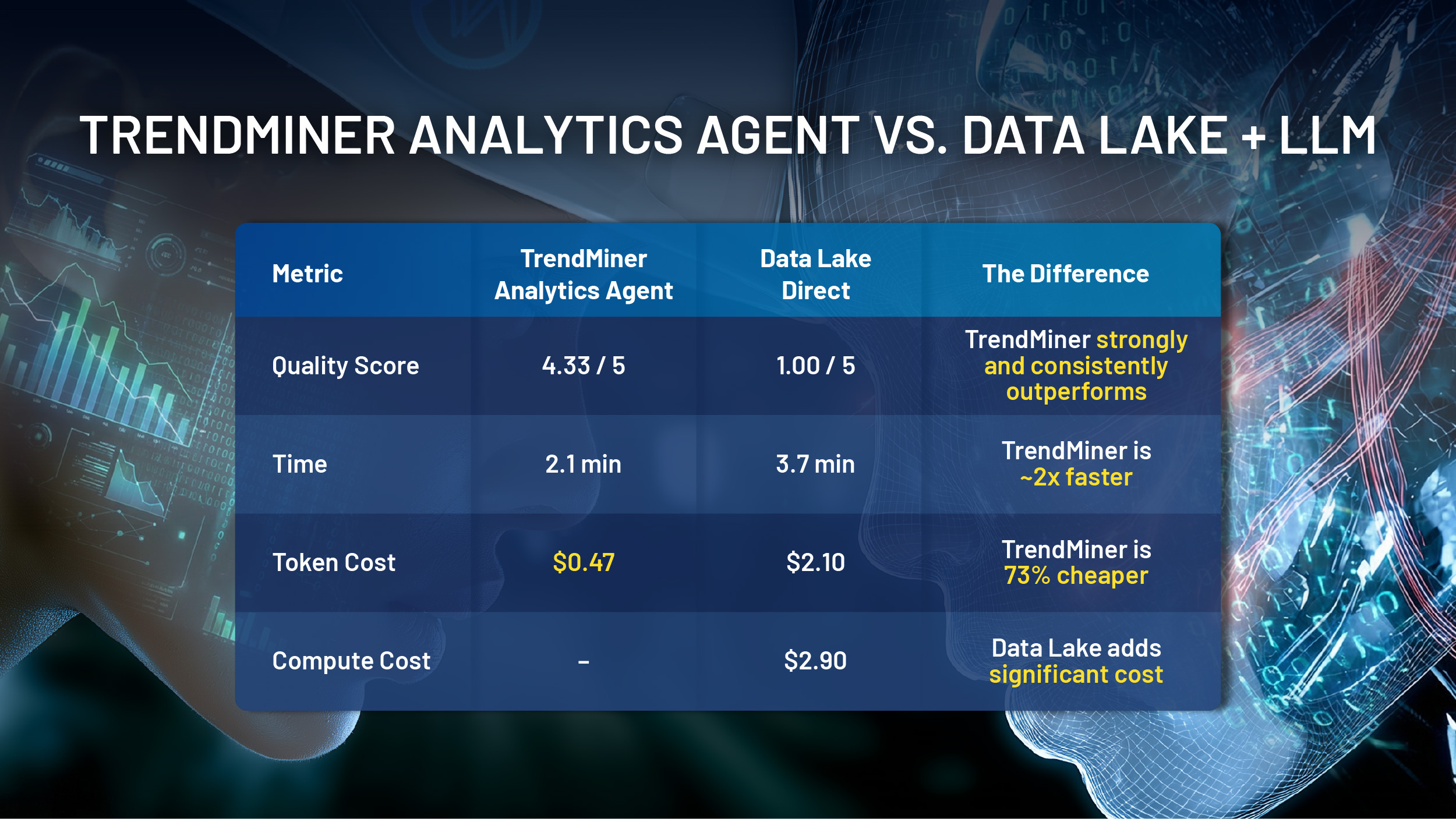
TrendMiner consistently matched or outperformed the data lake approach on quality across every comparison, while also completing them in roughly half the time (around 2 minutes versus 4 for the data lake). With capable models, the quality gap was stark: TrendMiner consistently scored above 4/5 while the data lake struggled to break 2.
The faster results tell only part of the story. TrendMiner delivered a better result in less time. That means less back-and-forth, fewer follow-up prompts, and less of the prompt fatigue that sets in when engineers have to repeatedly coax a useful answer out of an AI that’s struggling with the underlying data. On the data lake side, even when a run eventually produced a passable result, getting there often required multiple rounds of iteration and refinement. That hidden time cost (the engineer’s time) doesn’t show up in the benchmark metrics, but it’s very real in practice.
On the cost side, the advantage runs across both vectors: LLM token consumption was 73% lower thanks to the purpose-built analytics tools available in TrendMiner.file The data lake usually triggered a 2-3$ cost for query and compute resources per run due to the pay-as-you-go consumption model. Combined, these two factors make the total cost of the data lake approach multiple times higher per analysis.
Note: TrendMiner will also query the data. Inthe comparison case where TrendMiner is connected to on-premise data sources,there is no cost associated. When TrendMiner is connected to the data lake, itwill also trigger the cost, but only one time. Subsequent runs or differentanalyses using the same data would trigger zero additional costs.
The same mid-tier model that scored 4.3 / 5 on TrendMiner scored just 1.0 / 5 when pointed at the data lake. Same model, same prompt, same data. Radically different results.
That last finding is especially telling. The best-performing configuration in our benchmark was a mid-tier model paired with TrendMiner. The worst configuration? That exact same model pointed at the data lake, as it would trigger additional cost while still not reaching a qualitative answer. The model didn’t get dumber. It just lost the industrial context and purpose-built tooling it needed to do the job well.
What about model choice?
Our benchmark revealed a pattern worth calling out explicitly: the data lake approach only produced passable analysis when paired with the most expensive frontier-class model, and even then, it scored lower than a mid-tier model on TrendMiner at a fraction of the cost. In other words, the “just query the data lake” approach doesn’t just require more tokens per run; it requires a fundamentally more powerful (and expensive) model to compensate for the missing industrial context.
Advanced analytical tasks like root cause analysis and anomaly detection require genuine multi-step reasoning: forming hypotheses, retrieving the right data, interpreting results in context, and iterating. Lighter-weight models scored low on both integrations (roughly 1.7 / 5 across the board) because they lack the reasoning capacity to independently architect a complex investigation. A certain baseline of model intelligence is needed regardless of what sits underneath.
We’re transparent about this: no integration layer can fully compensate for insufficient model reasoning. This is an area we’re actively investing in. We’re building guided analytical workflows and pre-built skills that scaffold lighter-weight models through complex tasks step by step, reducing the reasoning burden so that more affordable models can deliver higher-quality results. But the honest takeaway today is this: model capability sets a floor; the integration layer determines how high above that floor you can reach. TrendMiner lifts the ceiling dramatically. The data lake approach forces you to pay for that ceiling with the most expensive model available and still delivers less.
Where the Data Lake Approach Broke Down
When you point an LLM at a raw data lake, you’re asking it to do an enormous amount of work before it even gets to analysis. It needs to discover the schema, figure out which tables and columns matter, write exploratory SQL, interpret results without domain context, and hope it asked the right questions. It’s the analytical equivalent of dropping someone into a foreign city without a map and asking them to find the best restaurant.
This problem compounds as tasks grow more sophisticated. For the root cause analysis, the data lake approach burned through tokens just figuring out which columns represented batch quality. For the continuous process tasks (anomaly detection on a distillation column, process stability assessment on a production line), the gap was even more pronounced. Continuous processes don’t have natural “batch” boundaries to anchor the analysis. The LLM querying raw tables had to invent its own segmentation logic, often producing arbitrary time windows that missed the actual operating context entirely.
In some cases, the model pointed at the data lake didn’t even understand the task. During the golden batch comparison, for example, the AI was asked to compare recent production runs against an optimal profile, a routine workflow for any process engineer. Despite several attempts, including the kind of follow-up prompting you could reasonably expect a user to try, the model could not grasp the concept of overlaying individual batch runs. Instead, it kept falling back to computing daily averages and attempting a root cause analysis on those aggregations, a fundamentally different (and useless) analysis. It wasn’t a model capability issue; the same model performed the task well on TrendMiner, where purpose-built batch comparison tools made the intent unambiguous.
TrendMiner’s Analytics Agent works fundamentally differently. Purpose-built tools like tag search, contextualized time-series retrieval, value-based filtering, and pattern recognition give the AI a guided, efficient path to the right data. For golden batch comparisons, the agent could directly leverage TrendMiner’s fingerprinting capabilities to overlay and compare runs. For process stability work, it could evaluate operating zones and detect drift using tools designed for exactly that purpose. The model spends its token budget on analysis, not on exploration.
This shows up clearly in the numbers: the data lake approach consumed roughly 500k tokens per run versus 173k for TrendMiner. That’s not just a cost issue. Every unnecessary token is a chance for the model to lose the thread, hallucinate, or go down a dead-end query path. It also means additional exploratory queries being fired against the data lake, each one consuming compute credits, just to figure out what to ask next.
Better Together: How TrendMiner and Your GenAI Investments Reinforce Each Other
This isn’t a story about picking sides. The organizations getting the most out of AI in process manufacturing aren’t choosing between their central GenAI initiatives and TrendMiner. They’re combining them.
Here’s how that works in practice. Central IT and data teams are building GenAI capabilities around document processing, knowledge management, reporting, and cross-functional workflows. That’s valuable work. But when those capabilities reach the factory floor and need to interact with time-series process data, they hit a wall: raw sensor data without industrial context results in noise, not insight.
TrendMiner bridges that gap. It contextualizes time-series data using the knowledge of process experts: fingerprints, event labels, operational context layers, and validated analytical workflows. When your GenAI platform needs to reason about process performance, it doesn’t have to start from scratch against a raw data lake. It can connect to TrendMiner’s contextualized, indexed, and curated data layer, dramatically improving both the quality and the efficiency of AI-driven analysis.
Think of it this way: your GenAI investments provide the reasoning engine. TrendMiner provides the industrial intelligence that makes that reasoning meaningful. One without the other leaves value on the table.
“But Won’t GenAI Close the Gap Over Time?”
It’s the natural follow-up question: models are improving rapidly, coding agents are getting more capable, and frontier models today can already do things that were impossible a year ago. Won’t the data lake approach eventually catch up?
We don’t think so. The reason is structural, not technological. The gap in our benchmark isn’t about model intelligence. It’s about the absence of industrial domain knowledge, purpose-built tooling, and operational workflows in the data lake approach. Smarter models won’t conjure batch phase awareness, golden batch fingerprinting, or validated pattern recognition out of thin air. Those capabilities are the result of over a decade of focused investment in industrial analytics.
Our own data actually illustrates this well. The frontier-class model (Opus 4.6) did manage a decent quality score on the data lake: 3.67 out of 5. So yes, throwing enough model horsepower at the problem gets you closer. But consider what that actually means in practice: that 3.67 still falls short of the 4.33 that a mid-tier model achieved on TrendMiner, while incurring an unsustainable cost exceeding 8$ in LLM tokens alone. So the strongest model available, at the highest possible cost, still couldn't match a cheaper model running on purpose-built tooling. As models get more capable, we expect the data lake quality scores to inch up further. But the cost, speed, and consistency disadvantages aren't going anywhere, and neither is the gap to what the same model can achieve when it has the right tools.
If anything, more capable models could widen the gap. A better reasoning engine primarily benefits more from better tools and richer context, which is exactly what TrendMiner provides. Our benchmark showed this clearly: the same mid-tier model that scored 4.3 on TrendMiner scored 1.0 on the data lake, which could reasonably be expected to be matched by the lowest-tier model in 12 months. The model’s intelligence didn’t change; the tooling did.
A fair counterargument: couldn’t a central engineering team, IT, or operational excellence group bridge that gap? Build custom agents, write detailed system instructions, create dedicated skills that teach the model how your data is structured? In theory, yes. In practice, you’d be attempting to rebuild from scratch what TrendMiner has spent over a decade refining: purpose-built industrial analytics with validated workflows, pattern recognition, and deep time-series expertise. And while your team is spending months building, testing, and maintaining that custom scaffolding, we’ll be investing that same time into pushing our platform even further. It’s a race you don’t need to run.
The research backs this up. MIT’s Project NANDA (The GenAI Divide: State of AI in Business 2025) studied hundreds of enterprise AI deployments and found that specialized vendor solutions succeed roughly twice as often as internal builds, with a 67% success rate versus about 33%. Some might argue that newer, more capable models and agentic coding tools have changed this equation. But the 2026 industry consensus tells the same story: the bottleneck is domain expertise, workflow integration, and the organizational effort required to build and maintain production-grade tooling. Those challenges don’t disappear because the underlying model got smarter. If anything, more capable models raise the bar for what “good” looks like, making purpose-built solutions even more important.
Enterprise Momentum: TrendMiner as Operational Infrastructure
There’s one more dimension that doesn’t show up in a benchmark but matters enormously in practice: organizational momentum.
If you’re one of our customers that have already invested in building TrendMiner into your core operational infrastructure, you’ll already have engineers across dozens of sites using it daily. Analytical workflows, monitors, dashboards, and knowledge bases have been built up over potentially thousands of use cases. Ways of working have been established, training programs rolled out, and continuous improvement cycles anchored to TrendMiner’s capabilities.
The cost of replacing that isn’t a software licensing decision. It’s an organizational transformation. Adoption, training, institutional knowledge, validated workflows, site-level customization: these represent years of accumulated value that can’t be replicated by pointing a new AI tool at a data lake. And for organizations still building this operational capability, TrendMiner offers a proven path that’s already been walked by the industry’s largest players.
And That’s Before You Count the Platform
Everything above focuses on the AI integration layer, specifically how TrendMiner’s Analytics Agent outperforms a raw data lake approach. But it’s worth stepping back to remember what you’re actually getting with TrendMiner beyond the AI story, because you will typically have to build out these capabilities on the other side of the comparison too.
A best-in-class trending client. Interactive, fast, built for industrial time-series data. Process engineers can visualize, overlay, and explore years of production data in seconds, without coding, no SQL, no waiting for a query to return. The Analytics Agent is powerful, but the visual exploration layer is where a lot of day-to-day insights will still happen for the foreseeable future.
Operationalize, don’t just analyze. An analysis that lives in a chat window and disappears is a missed opportunity. TrendMiner lets you turn findings into always-available dashboards, always-on monitors with alerting, and automated workflows that keep running long after the investigation is done. The path from insight to action is built in.
Capture and share knowledge. Every analysis can be saved, annotated, and shared with colleagues across shifts, sites, and departments. When a process engineer solves a problem, that knowledge doesn’t stay locked in their head or buried in a conversation log. Instead, it becomes part of the organization’s institutional memory. That’s how you build a culture of continuous improvement, not just a collection of one-off AI queries.
What This Means in Practice

The Bottom Line
“Just point the LLM at the data lake” sounds like a shortcut. In practice, it’s a detour. One that costs more, takes longer, and produces worse results. The question was never whether LLMs can query data lakes. Of course they can. The question is whether that’s good enough for industrial process analytics where quality, reliability, and auditability aren’t optional.
Our benchmark says it isn’t. And the answer isn’t to choose between GenAI and TrendMiner. Use both, each where it’s strongest. Let your central AI capabilities handle enterprise-wide workflows. Let TrendMiner handle the industrial analytics. The combination is where the real value lives.
Methodology: The benchmark suite comprised four analytical tasks spanning batch and continuous processes: root cause analysis, anomaly detection & diagnosis, golden batch comparison, and process stability assessment. Three AI models (lightweight, mid-tier, and frontier-class) each completed multiple repetitions per integration. Cost estimates are based on token usage at standard model pricing. Full benchmark details available on request.
Quality Scoring: Each run was evaluated independently on a 1–5 scale across five dimensions. The final quality score is the weighted average across all dimensions.











